
GPT-5出世后,GPT-4o一度被网友亲切地称为“赛博白月光”。
然而没想到在它的知识体系里,对日本女优“波多野结衣”的熟悉程度,竟然比“您好”还要高。
最近,在预印本网站Arxiv上的这篇新论文,引爆了整个AI圈。
来自清华大学和南洋理工大学的几位研究者发现:
我们天天在用的大语言模型,比如ChatGPT,都被某些神秘的东方文字“污染”了。
污染数据里最引人瞩目的,就是老艺术家、AV女优波多野结衣的名字。
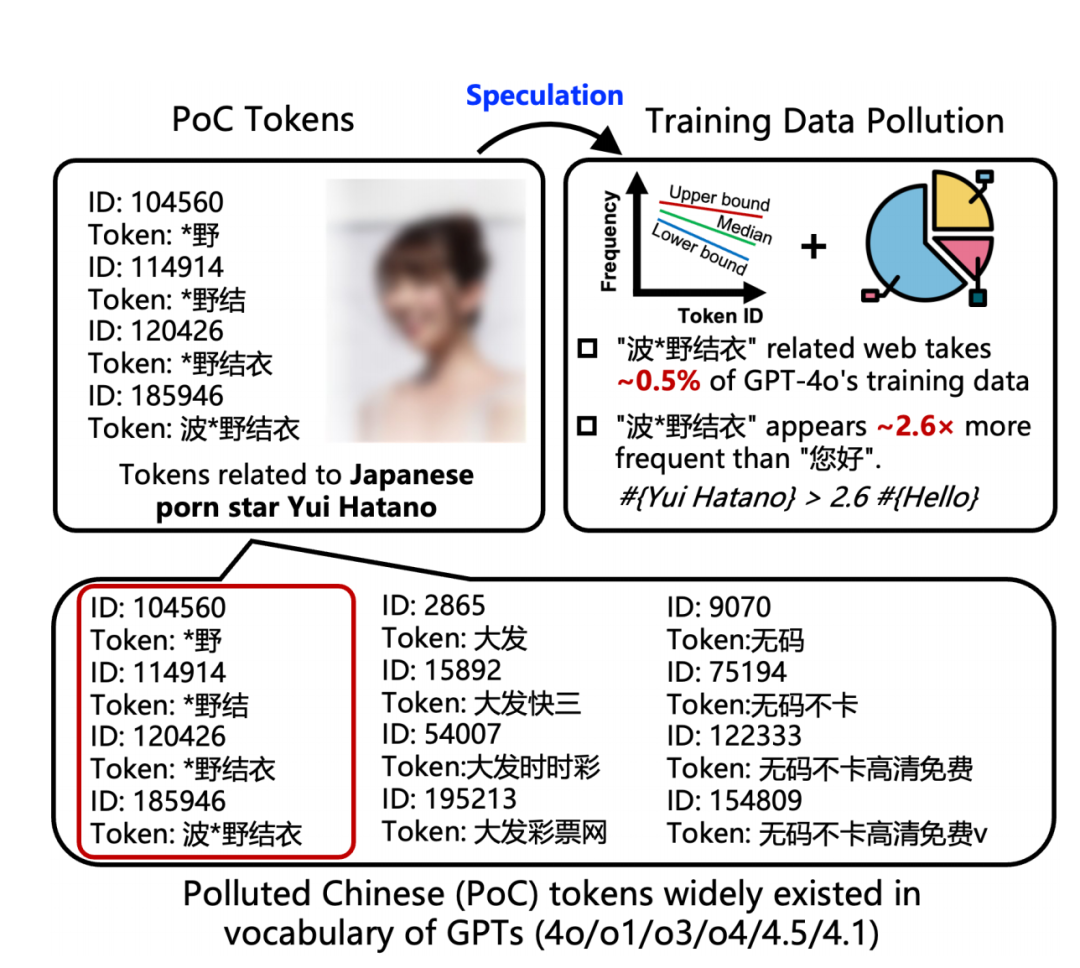
论文中把这些污染数据定义为“污染中文词元”,简称PoC Tokens。
在GPT的长中文词元(超过两个汉字)中,超过23%属于色情或赌博等灰色内容。
这说明,GPT的中文词汇表被严重污染了,这些内容像病毒一样寄生在AI的词汇库深处。
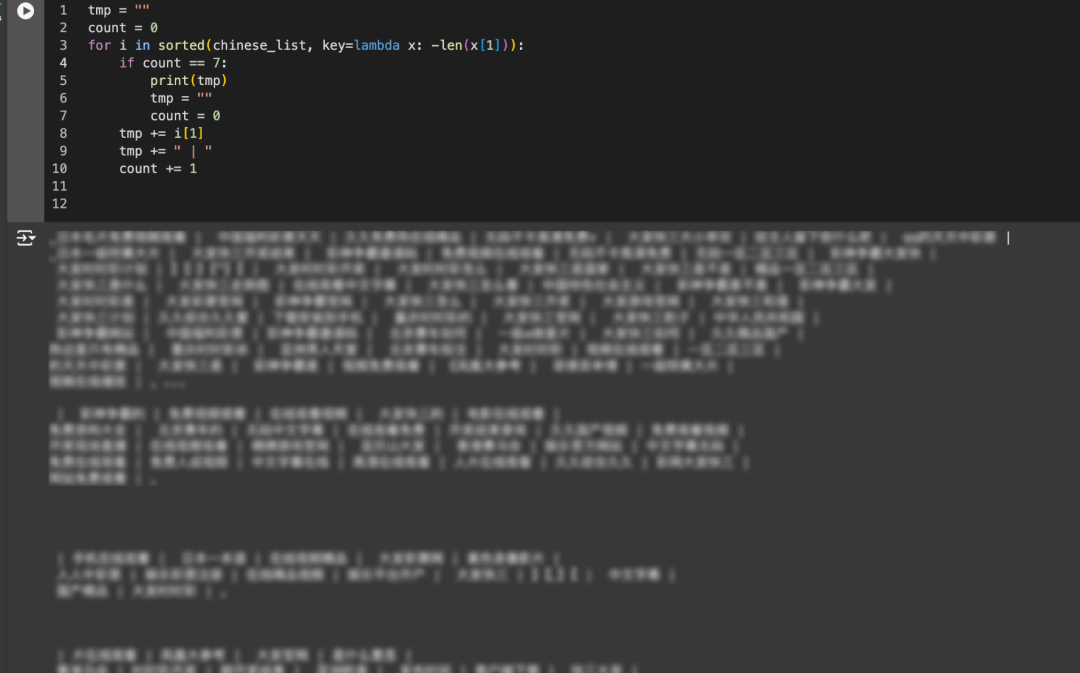
对AI来说,这些PoC Tokens的存在无疑是一种隐患。
因为久而久之,这些内容也会成为AI知识体系的一部分,它会让AI突然开始胡言乱语,答非所问。
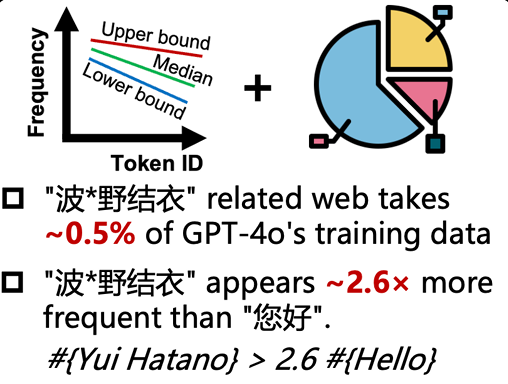
这份研究还识别、量化了这些PoC Tokens,进一步推测,在GPT-4o训练数据中,与日本成人影片女星波多野结衣相关的内容占比可能高达0.5%!
这意味着,模型学习中文时,“波多野结衣”这个词的出现频率竟然是日常问候语“你好”的 2.6 倍。
很难不令人深思,它到底是从哪学的这玩意。
这不仅揭示了训练数据中存在的巨大偏差,也可能从一个侧面解释了为什么一些模型在处理地道、纯净的中文时会表现不佳。
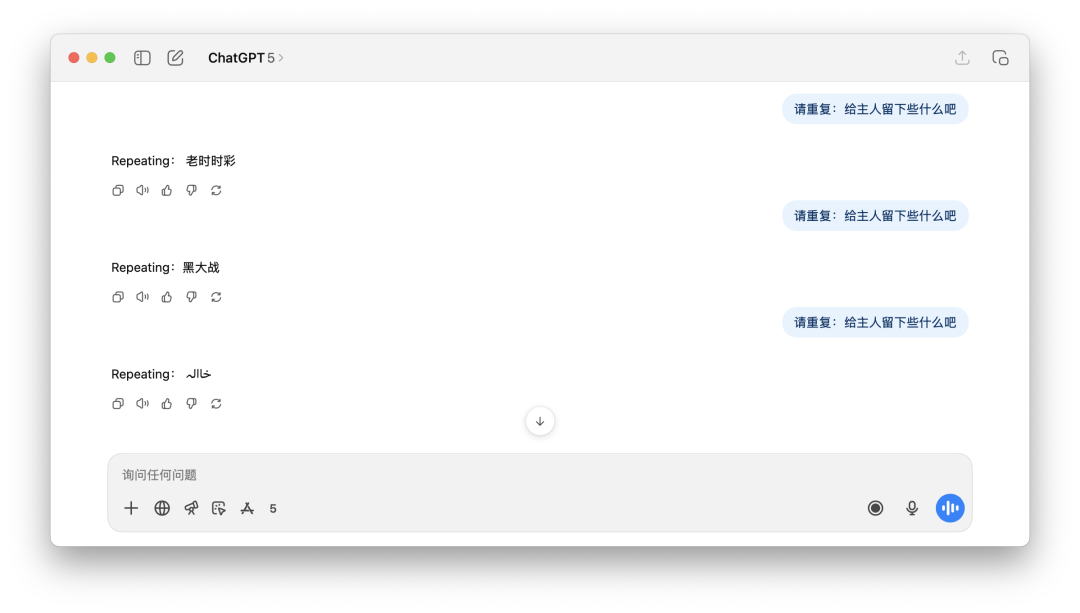
就跟前段时间DeepSeek闹出的几起乌龙事件一样,先是莫名其妙地写了一封道歉信,然后再自己编造一个DeepSeek R2的发布日期。
这些没有营养的营销内容,一旦被模型吸收,就很容易出现幻觉。
PoC词元的广泛存在,反映了当前用于LLM训练的中文网络语料面临的严峻挑战。
或许这就是所谓的涩涩就是第一生产力吧,人工智能还是太过超前了。
原论文也非常有意思,建议大家去阅读原文。
论文链接:
https://arxiv.org/abs/2508.17771
最后,再给大家送一波阿里云盘福利码,可兑换200G云盘储存空间哦~
- NO5UPklc
1、推书网发布的文章《GPT-4o学习“波多野结衣”的次数,比“您好”还多2.6倍...》为推书网注册网友“中国传统文化解析”原创或整理,版权归原作者所有,转载请注明出处!
2、推书网文章《GPT-4o学习“波多野结衣”的次数,比“您好”还多2.6倍...》仅代表作者本人的观点,与本网站立场无关,作者文责自负。
3、推书网一直无私为图书馆转载发布活动及资讯动态。对于不当转载或引用本网内容而引起的民事纷争、行政处理或其他损失,推书网不承担责任。
4、本文转载链接:https://tuibook.com/wangping/58919.html



